edsnlp.processing.multiprocessing
ForkingPickler [source]
Bases: Pickler
ForkingPickler that uses dill instead of pickle to transfer objects between processes.
register classmethod
Register a reduce function for a type.
MultiprocessingStreamExecutor [source]
feed_queue [source]
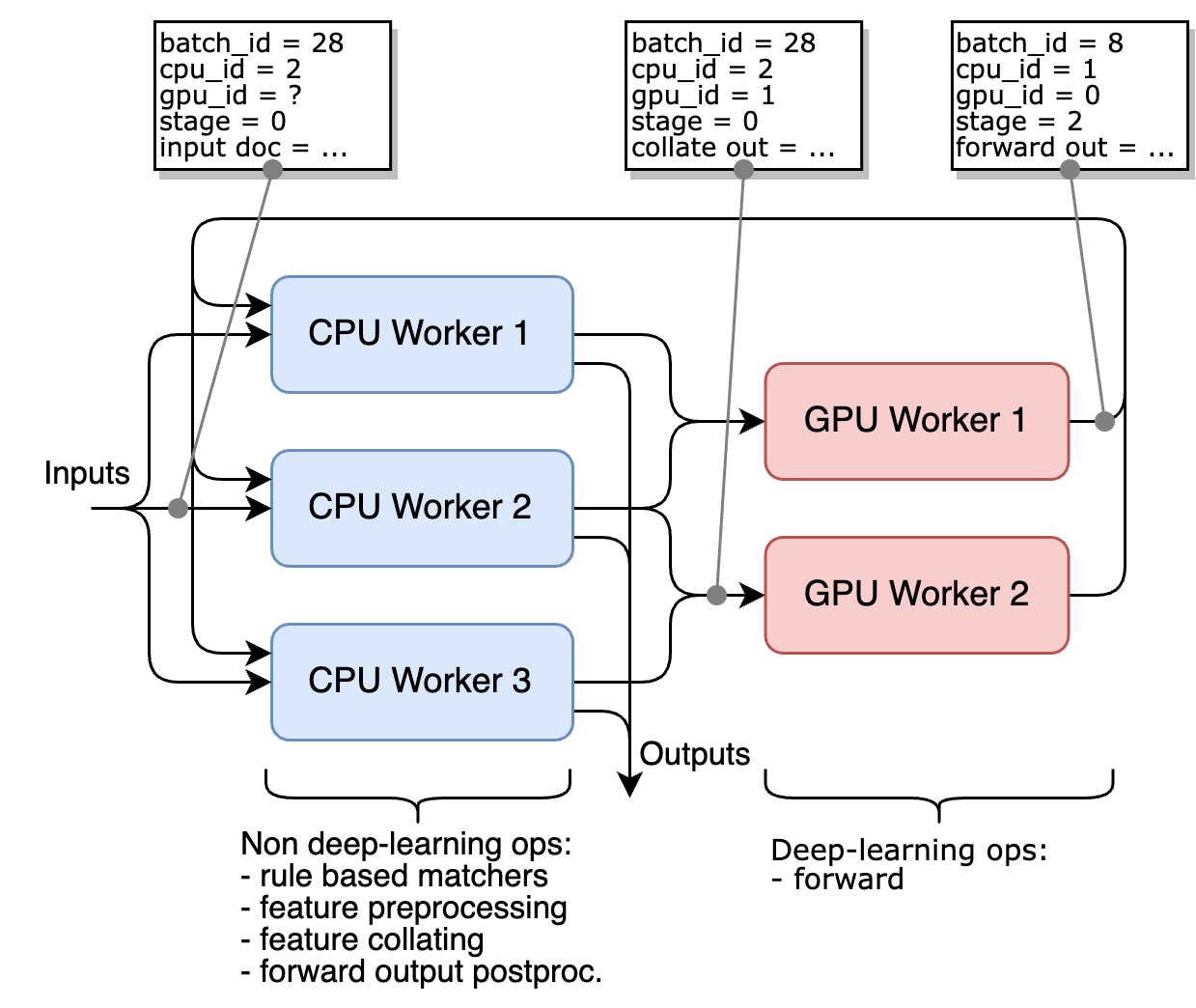
Enqueue items in a queue. Note that a queue may be shared between multiple workers, so have to send items destined multiple workers in the same queue. For that, we first determine which worker should receive the item based on the item index and some other env variables. Then we lookup the worker queue, and if it matches the current queue, we send the item, even if all workers share the same queue, in which case there is only on queue feeder thread that sends all the items (non-deterministic mode).
Parameters
| PARAMETER | DESCRIPTION |
|---|---|
queue | The queue to feed
|
items | The items to send. Note that this iterator is a tee of the main iterator, such that each worker can process items at its own pace.
|
replace_pickler [source]
Replace the default pickler used by multiprocessing with dill. "multiprocess" didn't work for obscure reasons (maybe the reducers / dispatchers are not propagated between multiprocessing and multiprocess => torch specific reducers might be missing ?), so this patches multiprocessing directly. directly.
For some reason I do not explain, this has a massive impact on the performance of the multiprocessing backend. With the original pickler, the performance can be up to 2x slower than with our custom one.
cpu_count [source]
Heavily inspired (partially copied) from joblib's loky (https://github.com/joblib/loky/blob/2c21e/loky/backend/context.py#L83) by Thomas Moreau and Olivier Grisel.
Return the number of CPUs we can use to process data in parallel.
The returned number of CPUs returns the minimum of: * os.cpu_count() * the CPU affinity settings * cgroup CPU bandwidth limit (share of total CPU time allowed in a given job) typically used in containerized environments like Docker
Note that on Windows, the returned number of CPUs cannot exceed 61 (or 60 for Python < 3.10), see: https://bugs.python.org/issue26903.
It is also always larger or equal to 1.
get_dispatch_schedule [source]
To which consumer should a given worker/producer dispatch its data to. This function returns a list of consumers over a period to be determined by the function.
This is actually a fun problem, because we want: - to distribute the data evenly between consumers - minimize the number of distinct unique producers sending data to the consumer (because we move the tensors to the GPU inside the producer, which creates takes a bit of VRAM for each producer)
Parameters
| PARAMETER | DESCRIPTION |
|---|---|
producer_idx | Index of the CPU worker TYPE: |
producers | Producers, ie workers TYPE: |
consumers | Consumers, ie devices TYPE: |
| RETURNS | DESCRIPTION |
|---|---|
List[T] | |
execute_multiprocessing_backend [source]
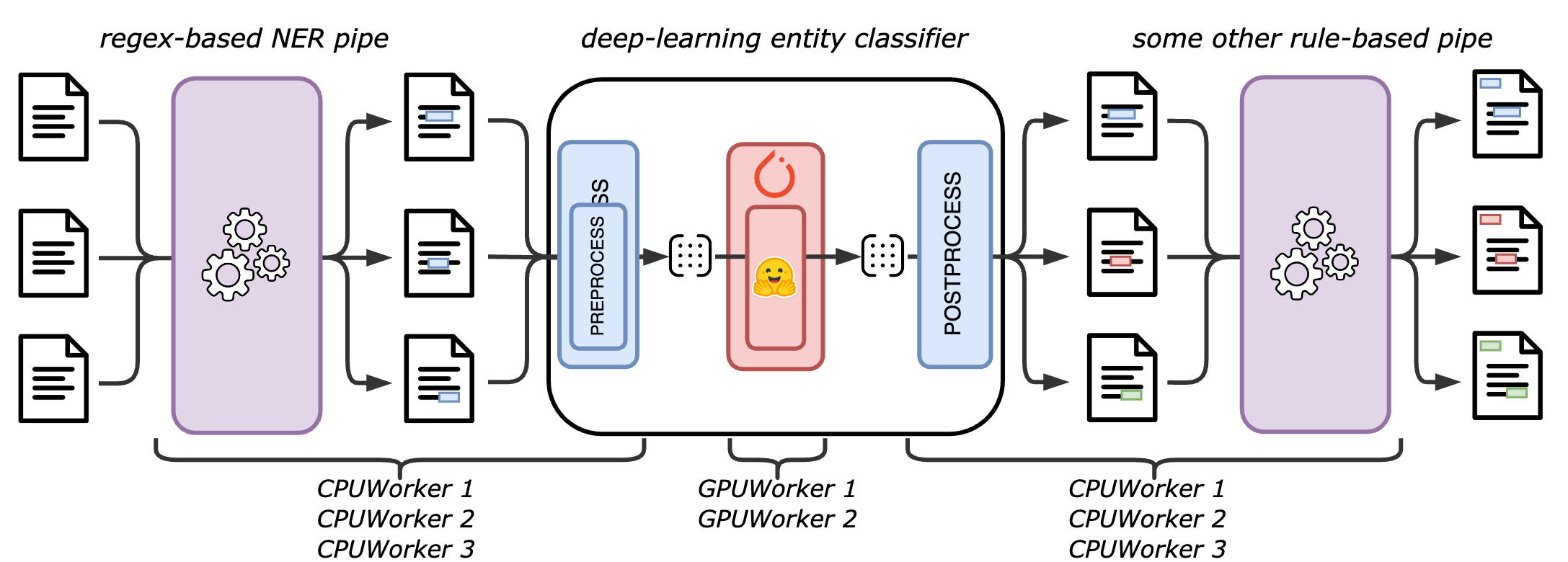
If you have multiple CPU cores, and optionally multiple GPUs, we provide the multiprocessing backend that allows to run the inference on multiple processes.
This accelerator dispatches the batches between multiple workers (data-parallelism), and distribute the computation of a given batch on one or two workers (model-parallelism):
- a
CPUWorkerwhich handles the non deep-learning components and the preprocessing, collating and postprocessing of deep-learning components - a
GPUWorkerwhich handles the forward call of the deep-learning components
If no GPU is available, no GPUWorker is started, and the CPUWorkers handle the forward call of the deep-learning components as well.
The advantage of dedicating a worker to the deep-learning components is that it allows to prepare multiple batches in parallel in multiple CPUWorker, and ensure that the GPUWorker never wait for a batch to be ready.
The overall architecture described in the following figure, for 3 CPU workers and 2 GPU workers.
Here is how a small pipeline with rule-based components and deep-learning components is distributed between the workers: